سرور بلید
A blade server is a stripped-down server computer with a modular design optimized to minimize the use of physical space and energy. Blade servers have many components removed to save space, minimize power consumption and other considerations, while still having all the functional components to be considered a computer. [1] Unlike a rack-mount server, a blade server needs a blade enclosure, which can hold multiple blade servers, providing services such as power, cooling, networking, various interconnects and management. Together, blades and the blade enclosure, form a blade system. Different blade providers have differing principles regarding what to include in the blade itself, and in the blade system as a whole.
In a standard server-rack configuration, one rack unit or 1U—19 inches (480 mm) wide and 1.75 inches (44 mm) tall—defines the minimum possible size of any equipment. The principal benefit and justification of blade computing relates to lifting this restriction so as to reduce size requirements. The most common computer rack form-factor is 42U high, which limits the number of discrete computer devices directly mountable in a rack to 42 components. Blades do not have this limitation. As of 2014, densities of up to 180 servers per blade system (or 1440 servers per rack) are achievable with blade systems.[2]
Blade enclosure
Enclosure (or chassis) performs many of the non-core computing services found in most computers. Non-blade systems typically use bulky, hot and space-inefficient components, and may duplicate these across many computers that may or may not perform at capacity. By locating these services in one place and sharing them among the blade computers, the overall utilization becomes higher. The specifics of which services are provided varies by vendor.

HP BladeSystem c7000 enclosure (populated with 16 blades), with two 3U UPS units below
Power
Computers operate over a range of DC voltages, but utilities deliver power as AC, and at higher voltages than required within computers. Converting this current requires one or more power supply units (or PSUs). To ensure that the failure of one power source does not affect the operation of the computer, even entry-level servers may have redundant power supplies, again adding to the bulk and heat output of the design.
The blade enclosure's power supply provides a single power source for all blades within the enclosure. This single power source may come as a power supply in the enclosure or as a dedicated separate PSU supplying DC to multiple enclosures.[3][4] This setup reduces the number of PSUs required to provide a resilient power supply.
The popularity of blade servers, and their own appetite for power, has led to an increase in the number of rack-mountable uninterruptible power supply (or UPS) units, including units targeted specifically towards blade servers (such as the BladeUPS).
Cooling
During operation, electrical and mechanical components produce heat, which a system must dissipate to ensure the proper functioning of its components. Most blade enclosures, like most computing systems, remove heat by using fans.
A servers. Newer blade-enclosures feature variable-speed fans and control logic, or even liquid cooling systems[5][6] that adjust to meet the system's cooling requirements.
At the same time, the increased density of blade-server configurations can still result in higher overall demands for cooling with racks populated at over 50% full. This is especially true with early-generation blades. In absolute terms, a fully populated rack of blade servers is likely to require more cooling capacity than a fully populated rack of standard 1U servers. This is because one can fit up to 128 blade servers in the same rack that will only hold 42 1U rack mount servers.[7]
Networking
Blade servers generally include integrated or optional network interface controllers for Ethernet or host adapters for Fibre Channel storage systems or converged network adapter to combine storage and data via one Fibre Channel over Ethernet interface. In many blades at least one interface is embedded on the motherboard and extra interfaces can be added using mezzanine cards.
A blade enclosure can provide individual external ports to which each network interface on a blade will connect. Alternatively, a blade enclosure can aggregate network interfaces into interconnect devices (such as switches) built into the blade enclosure or in networking blades.[8][9]
Storage
The ability to boot the blade from a storage area network (SAN) allows for an entirely disk-free blade, an example of which implementation is the Intel Modular Server System.
Other blades
Since blade enclosures provide a standard method for delivering basic services to computer devices, other types of devices can also utilize blade enclosures. Blades providing switching, routing, storage, SAN and fibre-channel access can slot into the enclosure to provide these services to all members of the enclosure.
Systems administrators can use storage blades where a requirement exists for additional local storage.[10][11][12]
Uses

Cray XC40 supercomputer cabinet with 48 blades, each containing 4 nodes with 2 CPUs each
Blade servers function well for specific purposes such as web hosting, virtualization, and cluster computing. Individual blades are typically hot-swappable. As users deal with larger and more diverse workloads, they add more processing power, memory and I/O bandwidth to blade servers. Although blade server technology in theory allows for open, cross-vendor system, most users buy modules, enclosures, racks and management tools from the same vendor.
Eventual standardization of the technology might result in more choices for consumers;[13][14] as of 2009 increasing numbers of third-party software vendors have started to enter this growing field.[15]
Blade servers do not, however, provide the answer to every computing problem. One can view them as a form of productized server-farm that borrows from mainframe packaging, cooling, and power-supply technology. Very large computing tasks may still require server farms of blade servers, and because of blade servers' high power density, can suffer even more acutely from the heating, ventilation, and air conditioning problems that affect large conventional server farms.
History
Developers first placed complete microcomputers on cards and packaged them in standard 19-inch racks in the 1970s, soon after the introduction of 8-bit microprocessors. This architecture was used in the industrial process controlindustry as an alternative to minicomputer-based control systems. Early models stored programs in EPROM and were limited to a single function with a small real-time executive.
The VMEbus architecture (ca. 1981) defined a computer interface which included implementation of a board-level computer installed in a chassis backplane with multiple slots for pluggable boards to provide I/O, memory, or additional computing.
In the 1990s, the PCI Industrial Computer Manufacturers Group PICMG developed a chassis/blade structure for the then emerging Peripheral Component Interconnect bus PCI which is called CompactPCI. Common among these chassis-based computers was the fact that the entire chassis was a single system. While a chassis might include multiple computing elements to provide the desired level of performance and redundancy, there was always one master board in charge, coordinating the operation of the entire system.
PICMG expanded the CompactPCI specification with the use of standard Ethernet connectivity between boards across the backplane. The PICMG 2.16 CompactPCI Packet Switching Backplane specification was adopted in Sept 2001.[16] This provided the first open architecture for a multi-server chassis. PICMG followed with the larger and more feature-rich AdvancedTCA specification, targeting the telecom industry's need for a high availability and dense computing platform with extended product life (10 years). While AdvancedTCA system and boards typically sell for higher prices than blade servers, AdvancedTCA promote them for telecommunications customers.
The first commercialized blade server architecture[citation needed] was invented by Christopher Hipp and David *******keby, and their patent (US 6411506) was assigned to Houston-based RLX Technologies.[17] RLX, which consisted primarily of former Compaq Computer Corporation employees, including Hipp and *******keby, shipped its first commercial blade server in 2001.[18] RLX was acquired by Hewlett Packard in 2005.[19]
The name blade server appeared when a card included the processor, memory, I/O and non-volatile program storage (flash memory or small hard disk(s)). This allowed manufacturers to package a complete server, with its operating system and applications, on a single card / board / blade. These blades could then operate independently within a common chassis, doing the work of multiple separate server boxes more efficiently. In addition to the most obvious benefit of this packaging (less space consumption), additional efficiency benefits have become clear in power, cooling, management, and networking due to the pooling or sharing of common infrastructure to support the entire chassis, rather than providing each of these on a per server box basis.
In 2011, research firm IDC identified the major players in the blade market as HP, IBM, Cisco, and Dell.[20] Other companies selling blade servers include AVADirect, Oracle, Egenera, Supermicro, Hitachi, Fujitsu, Rackable (hybrid blade), Cirrascale and Intel Corporation.
Blade models[edit]


Cisco UCS blade servers in a chassis
Though independent professional computer manufacturers such as Supermicro offer blade servers, the market is dominated by large public companies such as Cisco Systems, which had 40% share by revenue in Americas in the first quarter of 2014.[21] The remaining prominent brands in the blade server market are HPE, Dell and IBM, though the latter sold its x86 business to Lenovo in 2014.[22]
In 2009, Cisco announced blades in its Unified Computing System product line, consisting of 6U high chassis, up to 8 blade servers in each chassis. It has a heavily modified Nexus 5K switch, rebranded as a fabric interconnect, and management software for the whole system.[23] HP's line consists of two chassis models, the c3000 which holds up to 8 half-height ProLiant line blades (also available in tower form), and the c7000 (10U) which holds up to 16 half-height ProLiant blades. Dell's product, the M1000e is a 10U modular enclosure and holds up to 16 half-height PowerEdge blade servers or 32 quarter-height blades.
منبع : سرور بلید
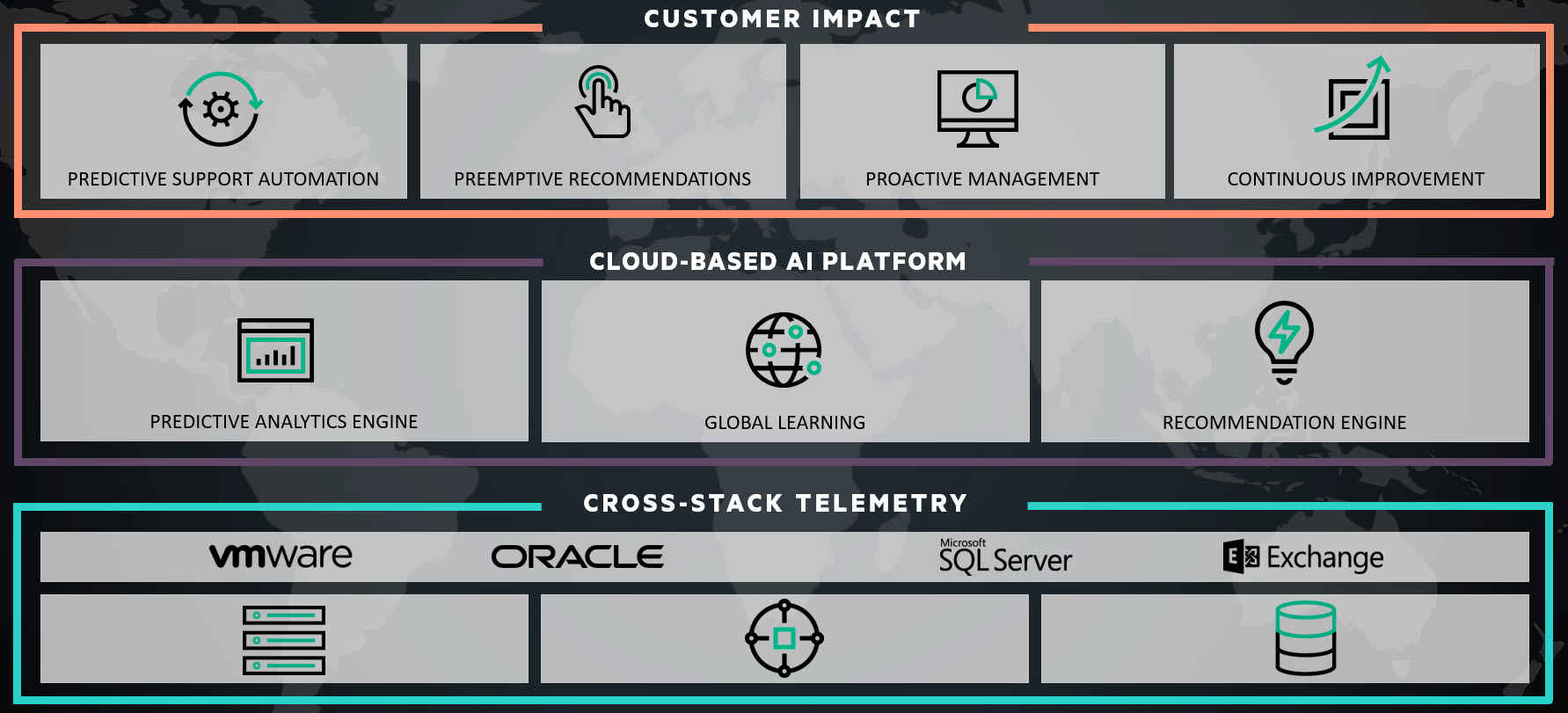
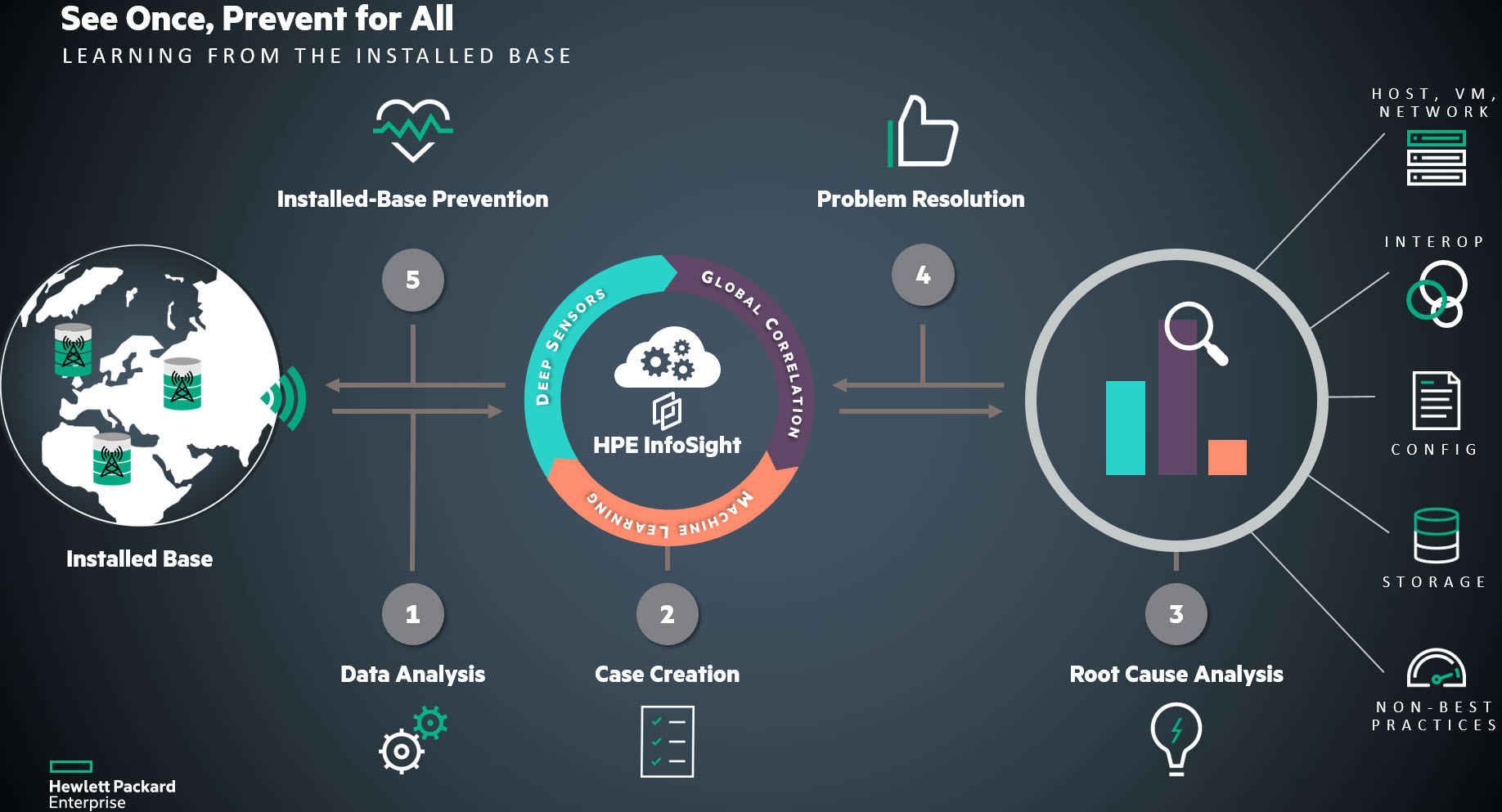
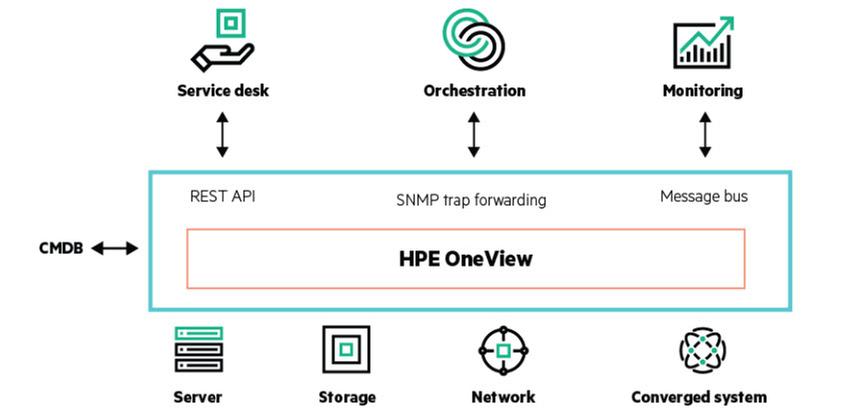
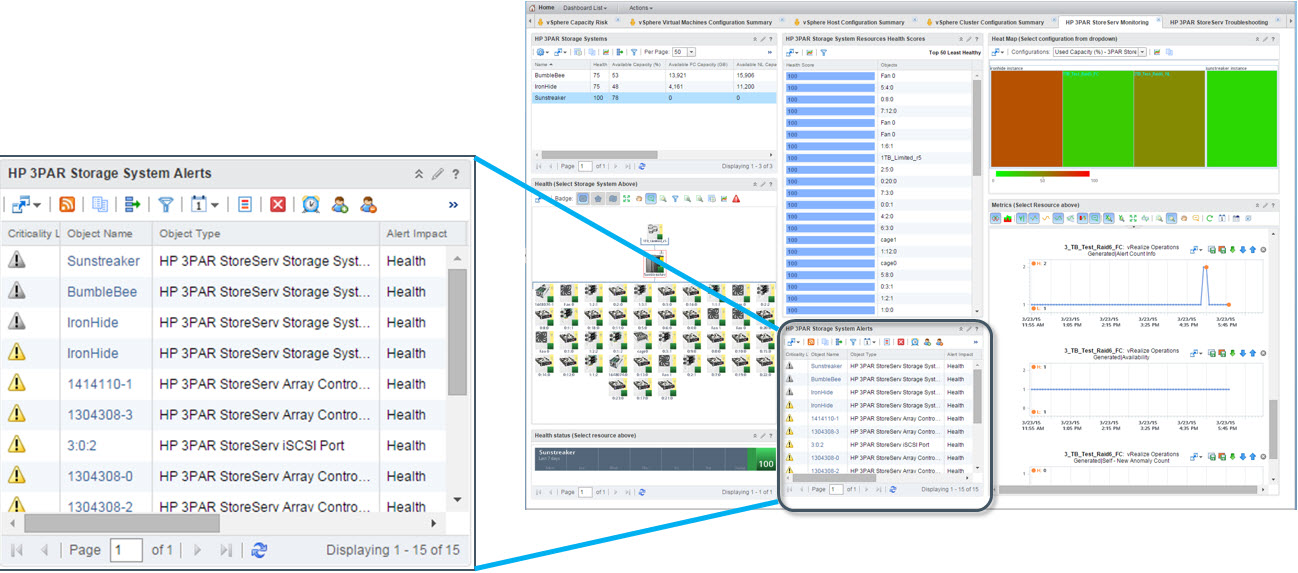
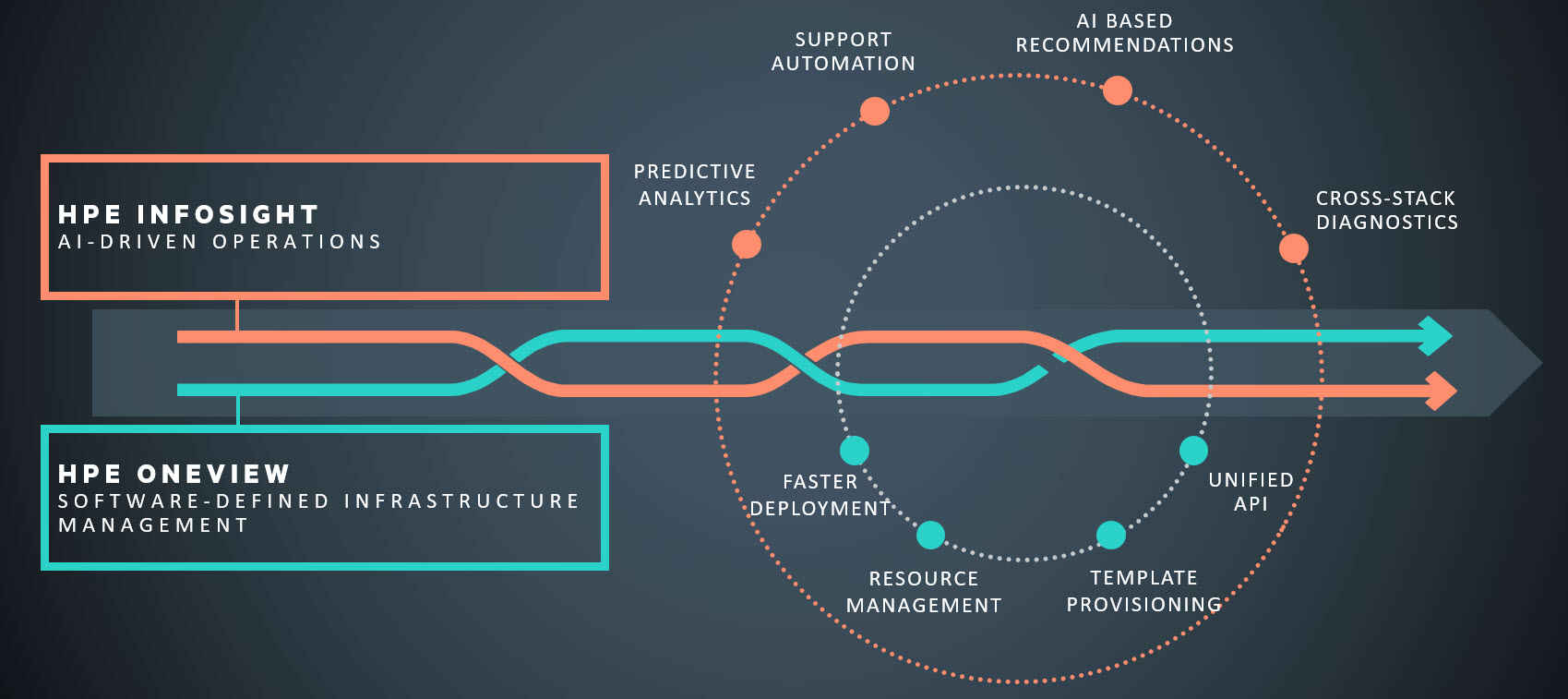
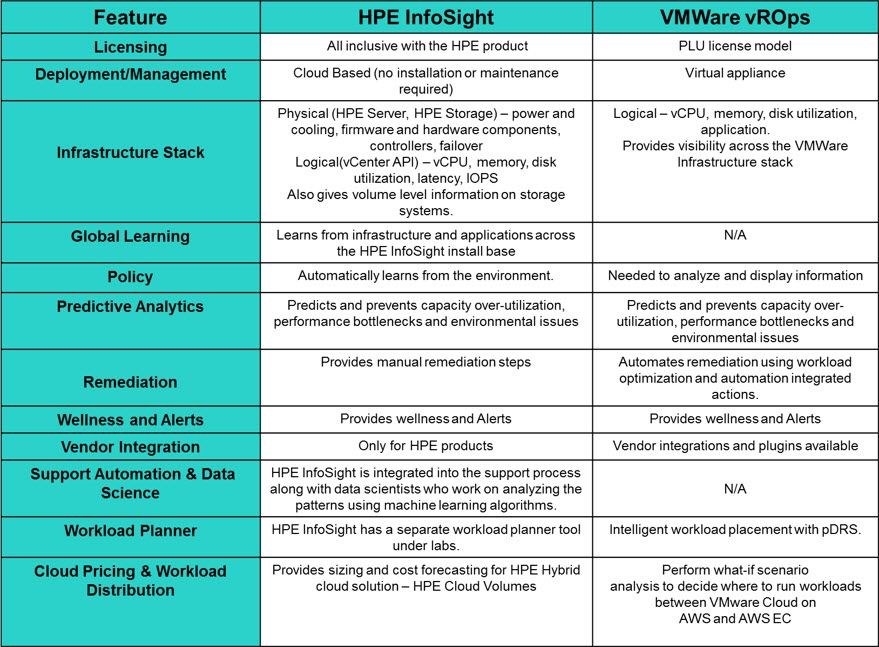
 ادغام vRealize Operations و HPE OneView[/caption]
ادغام vRealize Operations و HPE OneView[/caption]